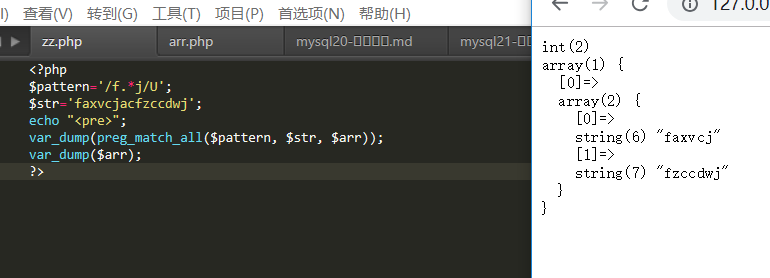
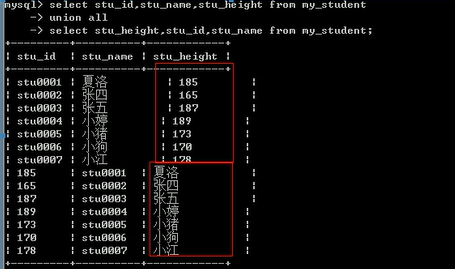
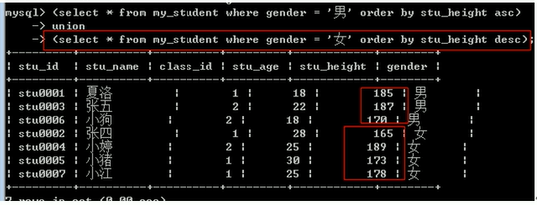
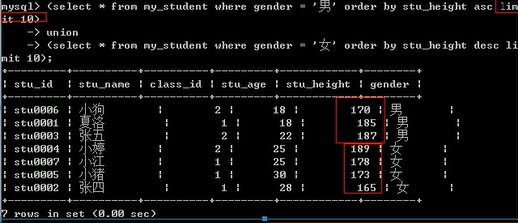
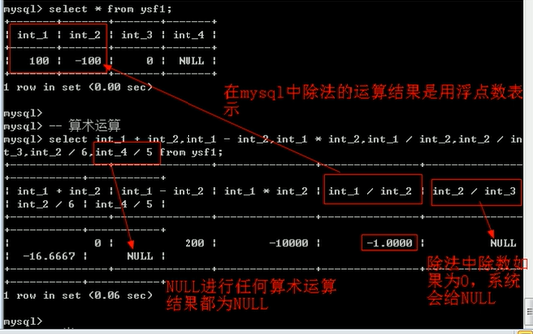
cookie
介绍
Cookie是用来将网站的资料记录在客户端的技术,这种技术让Web服务器能将一些资料,存放于客户端(用户的电脑)之中。 比如:当通过验证,成功登录网站后,在”网页一“的PHP脚本中,会把这个用户有关的信息,设置到客户端电脑的Cookie中,当再次访问同一个网站中的其他脚本时,就会自动携带Cookie中的数据一起访问,在服务器中的每个脚本中都可以接受Cookie中的数据,不需要每访问一个页面就重新输入一次登录者的信息。
Cookies最典型的应用是判定注册用户是否已经登录网站,用户可能会得到提示,是否在下一次进入此网站时保留用户信息以便简化登录手续,这些都是Cookies的功用。另一个重要应用场合是“购物车”之类处理。用户可能会在一段时间内在同一家网站的不同页面中选择不同的商品,这些信息都会写入Cookies,以便在最后付款时提取信息。
使用和禁用Cookie
用户可以改变浏览器的设置,以使用或者禁用Cookies。
微软Internet Explorer
工具 > Internet选项 > 隐私页
调节滑块或者点击“高级”,进行设置.
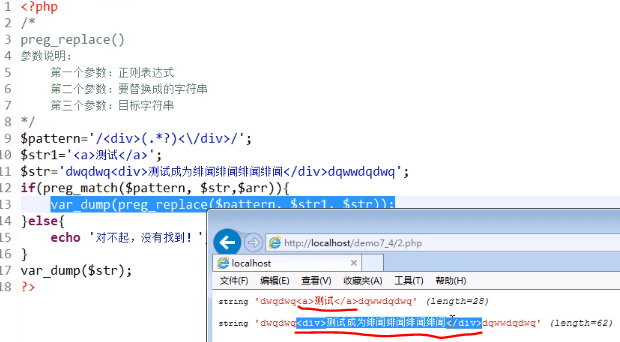
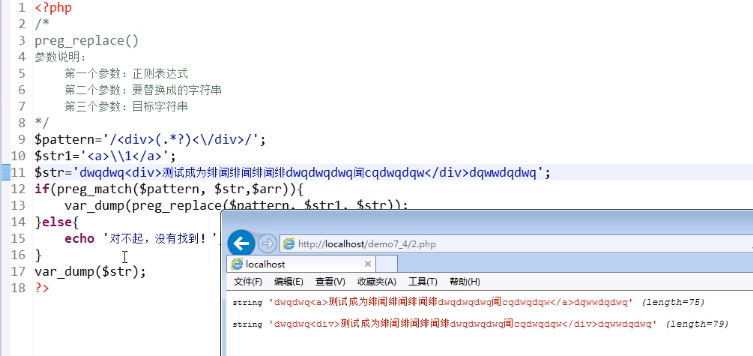
Mozilla Firefox
工具>选项>隐私
(注: 在Linux版本中,是如下操作:编辑 > 首选项 > 隐私 , 而Mac则是:Firefox > 属性 > 隐私)
查看源网页
查看源网页 [5]
设置Cookies选项
设定阻止/允许的各个域内Cookie
查看Cookies管理窗口,检查现存Cookie信息,选择删除或者阻止它们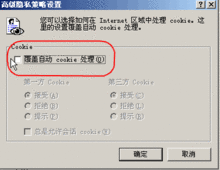
由于用户可能会禁用cookie那么使用替代方案:URL参数
Cookie操作:
1.向客户端电脑中设置Cookie
setcookie ();1
2
3
var_dump(uniqid(rand(1000,9999)));//设置cookie产生的随机数
2.在服务器端上读取Cookie的内容
$_COOKIE1
2
3
4
header('Content-type:text/html;charset=utf-8');
var_dump($_COOKIE);
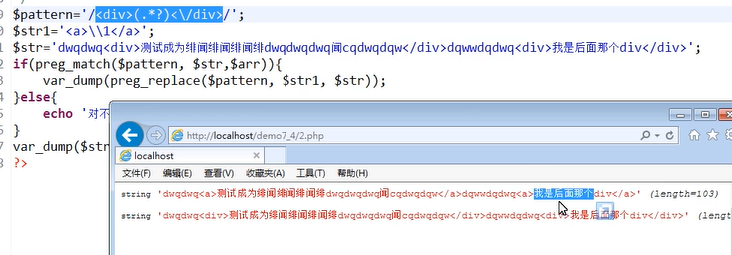
3.将多维数组应用于Cookie中
setcookie(“member[name]”,’孙胜利’);
setcookie(“member[email]”,'1205429372@qq.com‘);
一维数组:将所以cookie都直接保存在cookie数组下
使用二维数组,这样就能使多个cookie保存在cookie数组里的一个数组元素中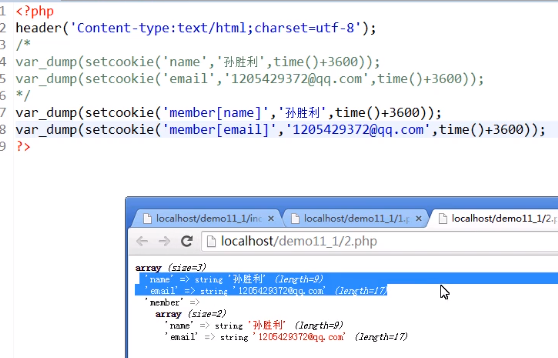
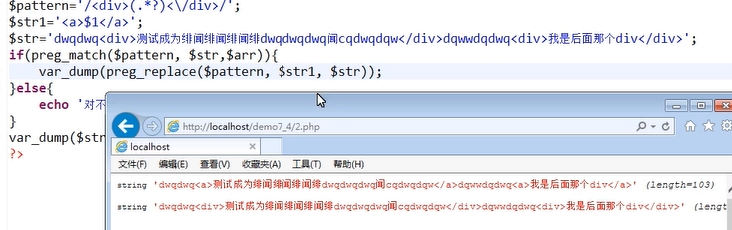
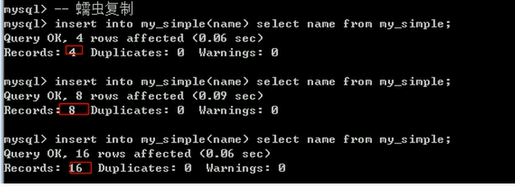
之所以还有上面的两个cookie是因为有效期还没过,我们删除之前的记录后: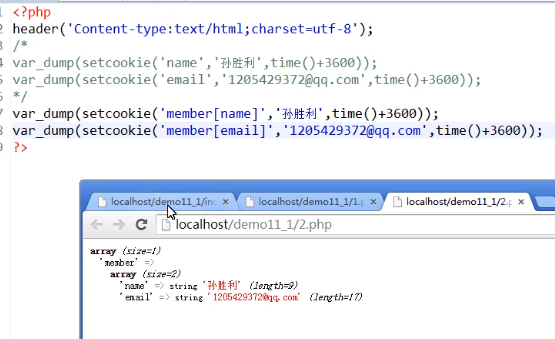
4.删除Cookie
setcookie(“member”,’’,time()-1);1
2
3
4
5
foreach ($_COOKIE['member'] as $key=>$val){
var_dump(setcookie("member[{$key}]",'',time()-3600));
}
注意点:使用setcookie删除cookie的时候,需要与当初设置cookie时的参数一致
session
Session技术与Cookie相似,都是用来存储使用者的相关资料,但是最大的不同之处在于Cookie是将资料存储在客户端电脑中,而Session则是将数据存放于服务器上。把保存的资料比喻成超市里面的会员卡,Cookie技术就相当于需要用户自己保存会员卡,每次去超市必须要持有会员卡才能代表自己的身份,那么Session技术就相当于会员卡由超市方保存,每次来超市的时候只需要报出会员卡的卡号(我们可以称为Session ID,客户端的cookie中只需要保存Session ID)即可!
session操作
1.开启session
session_start();//开启一个会话,或者返回已经存在的会话
2.使用session存储数据
session_start();
$_SESSION[‘username’]=’sunshengli’;
$_SESSION[‘email’]='1205429372@qq.com‘;
3.注销变量与销毁session1
2
3
4
5
6
session_start();//打开要销毁的会话!
session_unset();//Free all session variables 释放所有的会话变量
session_destroy();//销毁一个会话中的全部数据
setcookie(session_name(),'',time()-3600,'/');//销毁保存在客户端的卡号(session id)
注意:
如果此时我们不写第四个path参数即代码为:
setcookie(session_name(),’’,time()-3600)
此时我们查看session和cookie的销毁情况如下: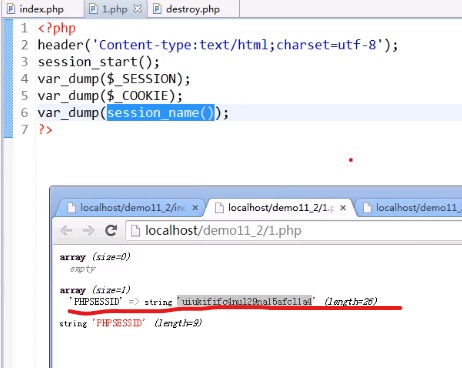
注意到cookie没有被删掉
原因:
PHP手册中setcookie里面的第四个参数:
path
Cookie 有效的服务器路径。 设置成 ‘/‘ 时,Cookie 对整个域名 domain 有效。 如果设置成 ‘/foo/‘, Cookie 仅仅对 domain 中 /foo/ 目录及其子目录有效(比如 /foo/bar/)。 默认值是设置 Cookie 时的当前目录。
而使用session时传的cookie位置是”/“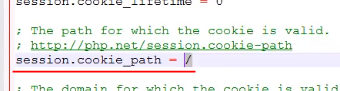
我们可以发现路径不一致,因此没有销毁对应的cookie
当我们设置好path参数后,成功删除客户端里的cookie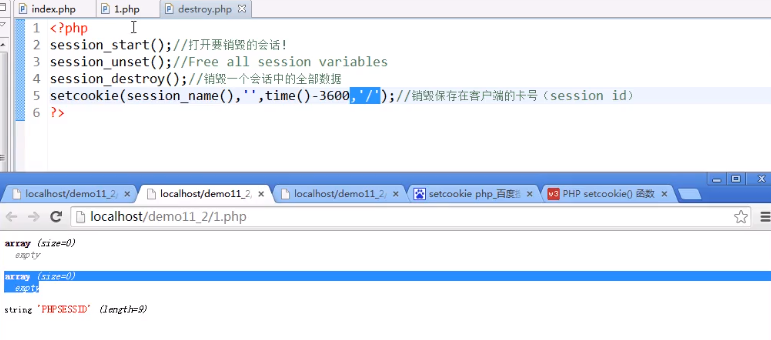
结论:
在销毁保存在客户端的时cookie时,要保证和当初设置的参数(path)一致。
在新的php中想获取session时,要先使用session_start();返回已经存在的会话。否则获取不到session
cookie与session
1>联系:Session在客户端也需要保存一个标识,所以就要借助Cookie,session是通过cookie来工作的session和cookie之间是通过$_COOKIE[‘PHPSESSID’]来联系的,通过$_COOKIE[‘PHPSESSID’]可以知道session的id,从而获取到其他的信息。
2>区别:Cookie机制采用的是在客户端(浏览器)保持状态的方案,而session机制采用的是在服务器端保持状态的方案