题目要求是二进制逆向
先用64位IDA打开,观察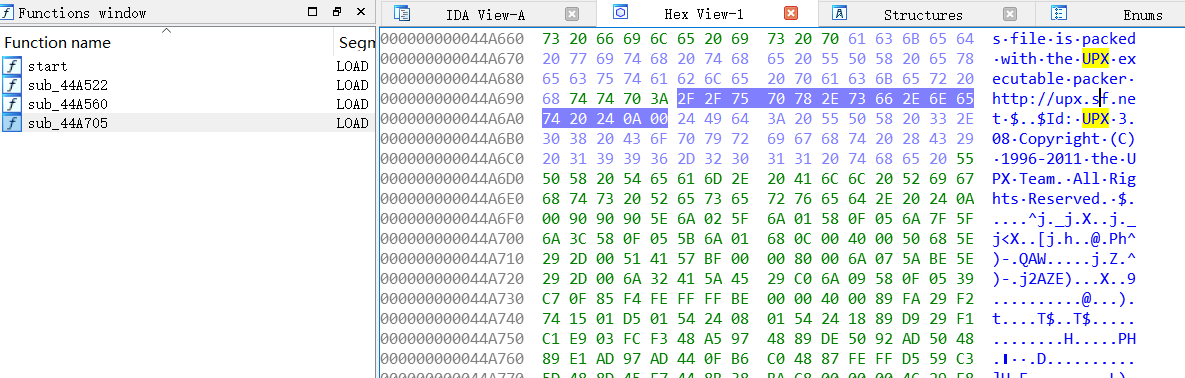
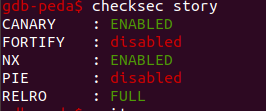
再根据题目中packed关键词推断存在加壳,再根据binary提示,使用winhex打开文件(也可查看IDA中Hex窗口)
可见存在UPX加壳,对于脱壳,Windows可以使用UPX Tool工具,Lunix可以使用命令upx -d 文件名
发现upx压缩了,linux下使用upx -d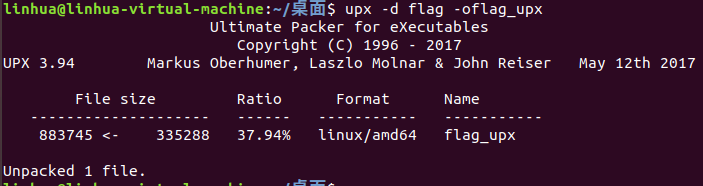
解压缩之后在ida载入,发现关键代码如下: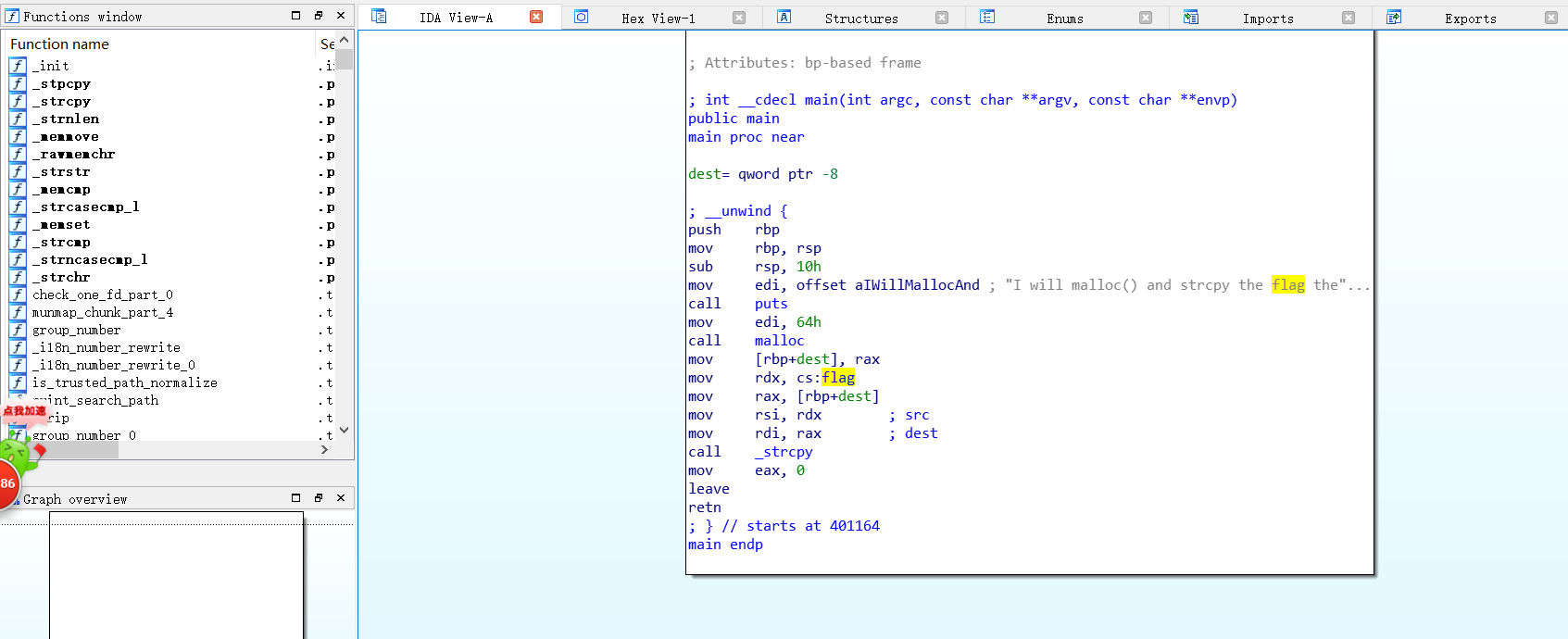
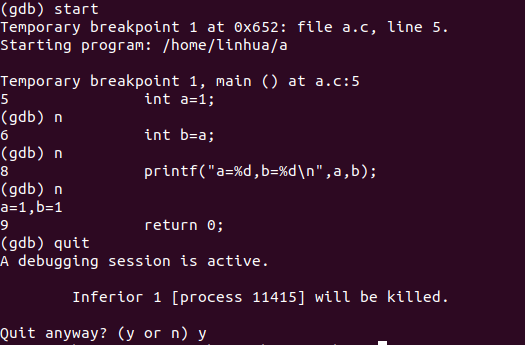
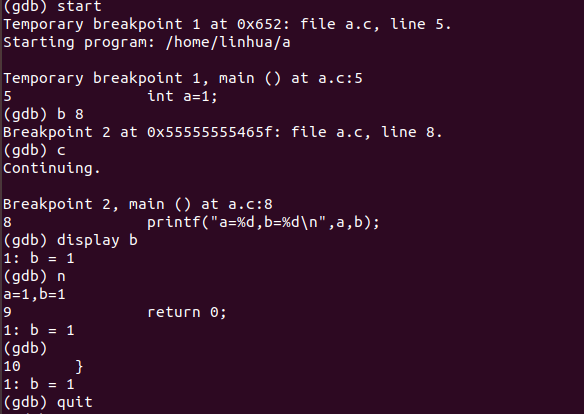
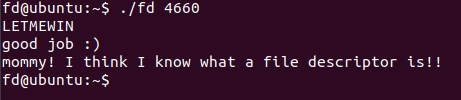
找到后,输入flag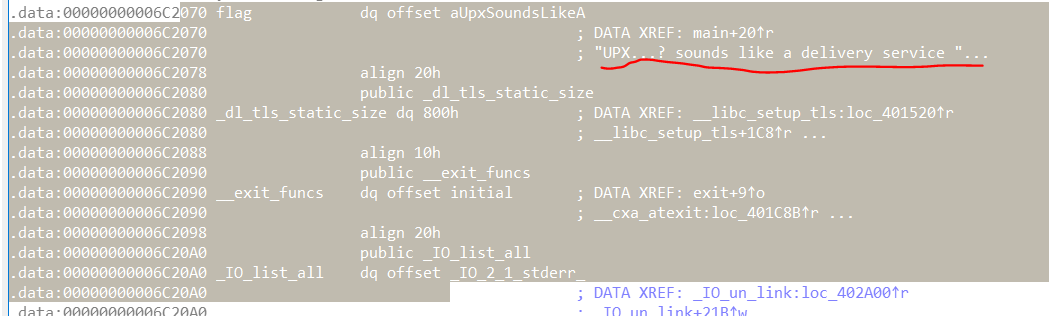
发现不对
所以是显示不完全
双击 进一步查看
或者将脱壳后的文件再用WinHex打开,搜索文本UPX得到flag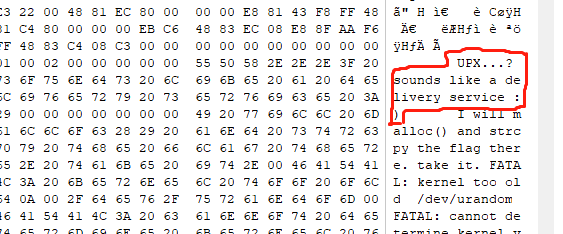
flag = UPX…? sounds like a delivery service :)

/1.PNG)
/p.PNG)
/p2.PNG)
/p3.PNG)
/3.PNG)