一、 正则表达式介绍
描述了一类字符串的特征,然后通过这个特征可以配合一些特定的函数,来完成对字符串更加复杂的一系列操作!
普通字符和特殊字符组成的一个字符串
1. 用途:匹配、查找、替换、分割
2. php提供了两套正则表达式函数库
(1). Perl 兼容正则表达式函数(推荐使用)
(2). POSIX 扩展正则表达式函数
二、语法规则
表达式的格式: "/表达式/[修正符]"
其中修正符是可选的,表示对表达式做额外的修饰。
我们一般习惯使用正斜线”/“作为定界的字符,前后一致
注意:定界符不可以是字母、数字和斜线\。
像“#”、“|”、“!”等都可以的
如:/…/ #…# |….|
三、 正则表达式的组成部分:
1. 基本单位(原子)
原子是组成正则表达式的基本单位,在分析正则表达式时,应作为一个整体。
原子包括以下内容:
* 单个字符、数字,如a-z,A-Z,0-9。
* 模式单元,如(ABC)可以理解为由多个原子组成的大的原子。
* 原子表,如 [ABC]。
* 重新使用的模式单元,如:\\1
* 普通转义字符,如:\d, \D, \w
* 转义元字符,如:\*,\.
* 元字符
2. 元字符(具有特殊意义字符):
各个字符含义
[] 表示单个字符的原子表
例如:[aoeiu] 表示任意一个元音字母
[0-9] 表示任意一位数字
[a-z][0-9]表示小写字和一位数字构成的两位字符
[a-zA-Z0-9] 表示任意一位大小字母或数字
[^] 表示除中括号内原子之外的任何字符 是[]的取反
例如:[^0-9] 表示任意一位非数字字符
[^a-z] 表示任意一位非小写字母
{m} 表示对前面原子的数量控制,表示是m次
例如:[0-9]{4} 表示4为数字
[1][3-8][0-9]{9} 手机号码
{m,} 表示对前面原子的数量控制,表示是至少m次
例如: [0-9]{2,} 表示两位及以上的数字
{m,n}表示对前面原子的数量控制,表示是m到n次
例如: [a-z]{6,8} 表示6到8位的小写字母
* 表示对前面原子的数量控制,表示是任意次,等价于{0,}
+ 表示对前面原子的数量控制,表示至少1次,等价于{1,}
? 表示对前面原子的数量控制,表示0次或1次(可有可无) 等价于{0,1}
例如:正整数:[1-9][0-9]*
整数:[\-]?[0-9]+
() 表示一个整体原子,还有一个子存储单元的作用【使用\\数字或$数字来代表圆括号部分所匹配到的内容】。
也可以使用?:来拒绝子存储。 (?:.*?)
例如:(red) 字串red
(rea|blue) 字串red或blue
(abc){2} 表示两个abc
| 表示或的意思
(rea|blue) 字串red或blue
^ 用在正则单元块的开头处,表示必须以指定的开头
$ 用在正则单元块的结尾处,表示必须以指定的结尾
. 表示任意一个除换行符之外的字符
()的使用:
如果使用对应的\\数字或$数字来代表圆括号部分所匹配到的内容,那么要注意匹配完整
由于没用匹配到\\1对应的e,匹配失败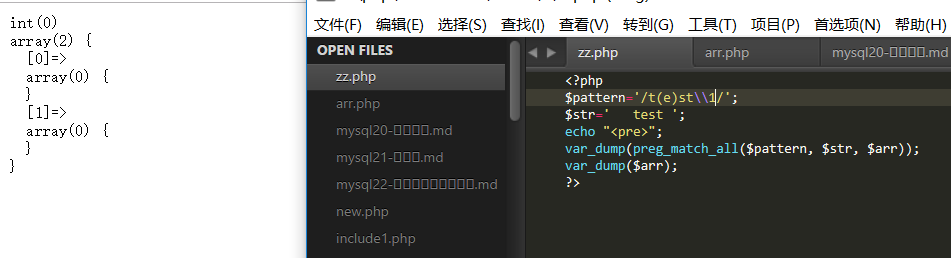
只有对应的内容都匹配到了才是匹配成功。array数组中分别保存了匹配的完整字符串,和()所匹配到的字符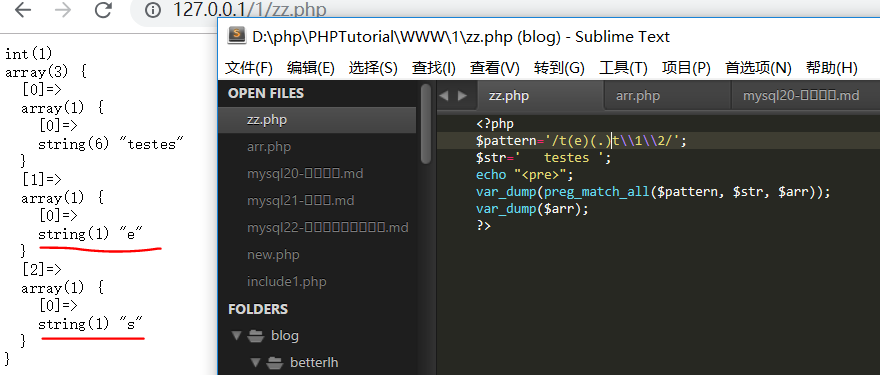
常用组合(贪婪匹配问题)
.与{n}配合 中间有n个非空
.与*配合 默认是贪婪匹配(尽可能多的去匹配字符) 中间有任意个非空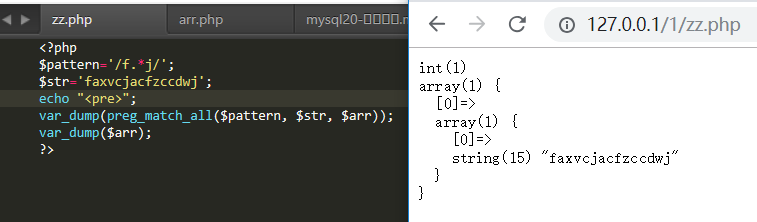
.*? 可以解决贪婪匹配(表示最小匹配所有字符)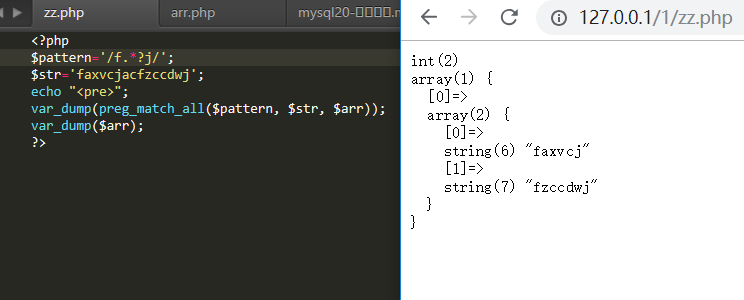
也可以使用模式修正符来解决: m
3. 普通转义字符:
\d 匹配一个数字;等价于[0-9]
\D 匹配除数字以外任何一个字符;等价于[^0-9]
\w 匹配一个英文字母、数字或下划线;等价于[0-9a-zA-Z_]
\W 匹配除英文字母、数字和下划线以外任何一个字符;等价于[^0-9a-zA-Z_]
\s 匹配一个空白字符;等价于[\f\n\r\t\v]
\S 匹配除空白字符以外任何一个字符;等价于[^\f\n\r\t\v]
\f 匹配一个换页符等价于 \x0c 或 \cL
\n 匹配一个换行符;等价于 \x0a 或 \cJ
\r 匹配一个回车符等价于\x0d 或 \cM
\t 匹配一个制表符;等价于 \x09\或\cl
\v 匹配一个垂直制表符;等价于\x0b或\ck
\oNN 匹配一个八进制数字
\xNN 匹配一个十六进制数字
\cC 匹配一个控制字符
4. 常见模式修正符
常见四种
i 在和模式进行匹配时不区分大小写"/[a-zA-Z]/" <==>"/[a-z]/i"
m 多行匹配,如果目标字符串 中没有"\n"字符, 或者模式中没有出现^或$, 设置这个修饰符不产生任何影响
s 如果设定了此修正符,那么.将匹配所有的字符包括换行符(表示匹配视为单行:就是可以让点.支持换行)
U 禁止贪婪匹配
U 禁止贪婪匹配
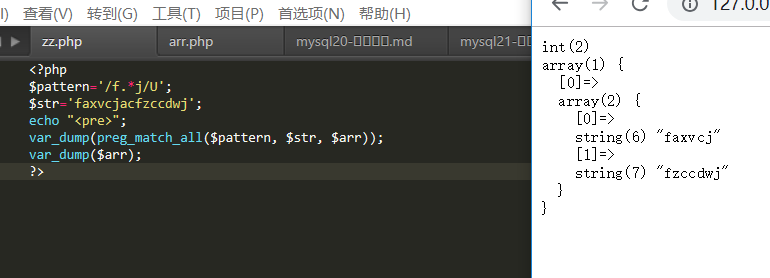
i 不区分大小写
如果设置了这个修饰符,模式中的字母会进行大小写不敏感匹配。
m 多行匹配
(如果目标字符串中没用“\n”字符,或者模式中没用出现^或$,设置这个修饰符不产生任何影响)
使用条件
- 目标字符串必须包含换行符“\n” 字符串中出现\n就表示新的一行开始
- 正则表达式中必须要出现^或者$
未使用修正符时: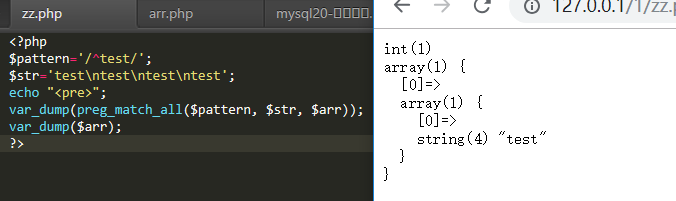
此时使用模式修正符,发现没用改动!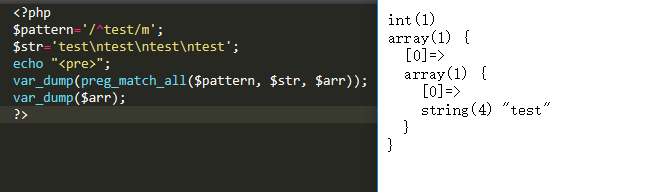
为什么?
因为在单引号里面不识别转义\n,它认为是普通的字符,而不是换行!!!
因此,我们将单引号换成双引号(我们可以发现\n有了高亮,实现了转义)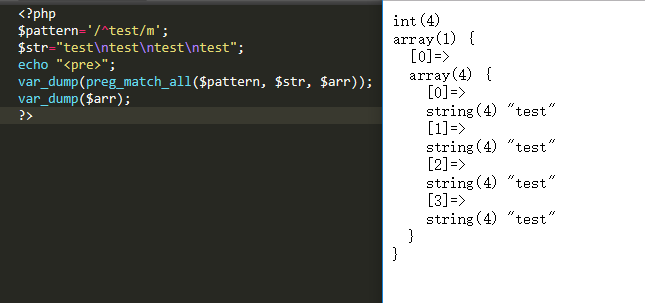
此时发现,m 模式修饰符起到了作用
换成以test结束试试(使用$)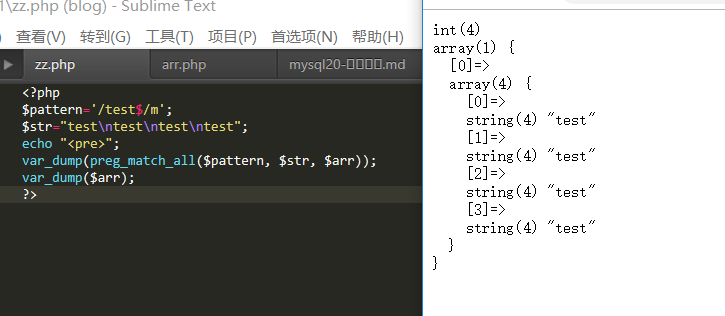
依旧可以
\n代表着换行那么,我们手动换行试试?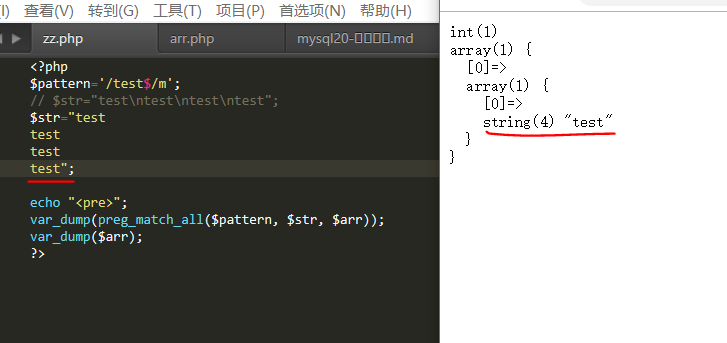
只能匹配一个,此时匹配的是最后一个
为什么?
解释:
在windows操作系统中,我们所看到的换行(肉眼看到的换行现象),其实是通过两个字符来完成的(\r\n)
在linux操作系统中看,我们所看到的换行(肉眼看到的换行现象),是通过\n来完成的
如果是这样,我们修改匹配规则: $pattern=’/test\r$/m’;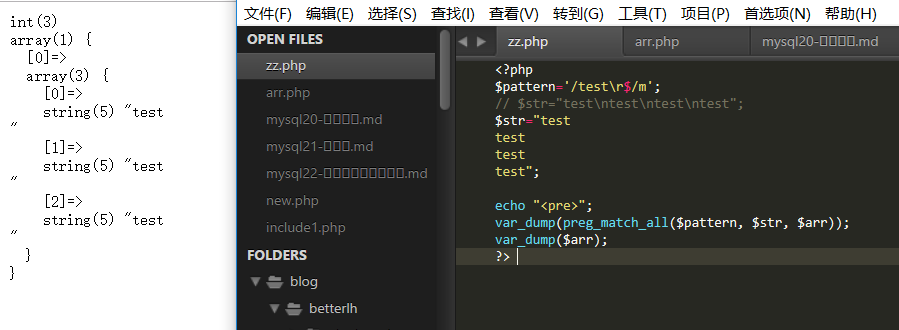
发现匹配到了三个,此时应为前三个匹配到
那么我们如何在windows如何匹配到四个呢?我们可以使用*来使得\r出不出现都能匹配到1
$pattern='/test\r*$/m';

此时成功匹配到四个
s 让点.支持换行
如果设置了这个修饰符,模式中的点号元字符匹配所有字符,包含换行符。如果没有这个 修饰符,点号不匹配换行符
不使用s 修正符时
使用s修正符: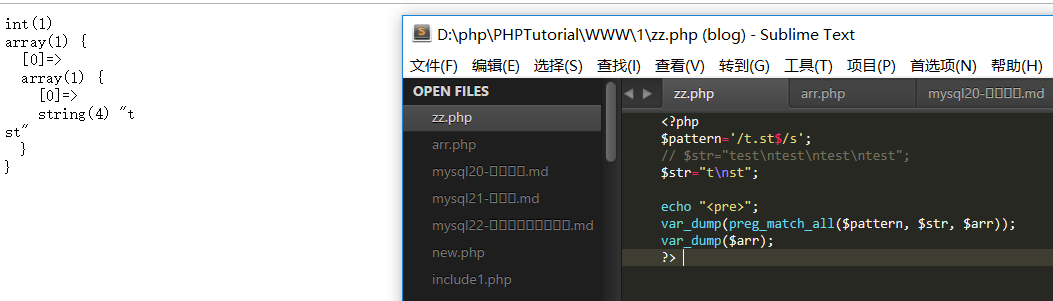
使用手动回车代替\n时: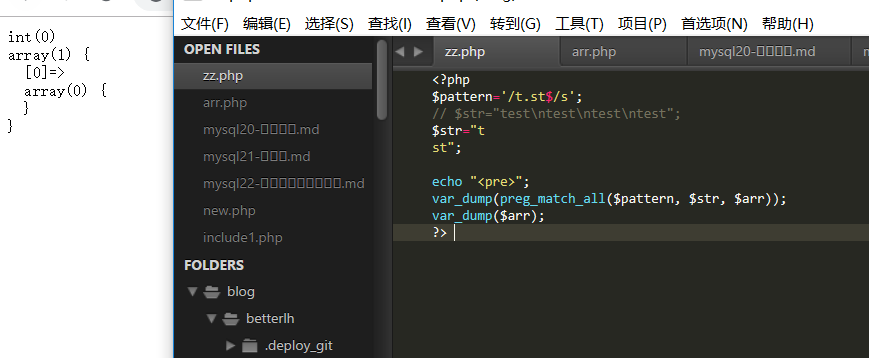
发现:同样我们在使用模式修正符s时,如果我们不是写\n而是手动回车也会发生同样的错误
补充:
\r 回车符
\n 换行符
两者区别
以下代码摘自网络:本帖最后由 rossini23 于 2011-05-26 23:48 编辑
1 |
|
1 | 1. |
第一条打印语句,\r使光标移动到本行行首,然后打印a test覆盖this i,变成a tests
第二条打印语句,\n使光标移动到下一行行首,然后打印a test
第三条打印语句,\r\n使光标移动到本行行首,然后移动到下一行行首,然后打印a test
然后在linux下,用stty设置关闭ONLCR转换:
stty -onlcr
发现输出变为:
1. a tests
2. this is
3. a test
4. this is
5. a test
看起来,第二条打印语句的\n行为是“将光标移动到下一行当前位置”
在linux系统下,onlcr是控制nl转换到cr nl。
也就是说正常情况下\n被转换成了\r\n,然后送到屏幕上显示,所以第二个输出语句看到的效果是回到下一行行首。
stty -onlcr也就是关闭nl转换到cr nl,这时候送到屏幕上的只有\n,看到结果是移动到下一行当前位置。
\r\n是一个让人郁闷的问题,windows和我们的嵌入式系统之间交互总是有问题,所以想搞明白这个问题。
网络上搜\r\n也可以看到很多OS之间、协议之间交互的问题。
四、 正则表达式的函数:
preg_grep -- 返回与模式匹配的数组单元
**preg_match_all** -- 进行全局正则表达式匹配 , 返回共计匹配的个数。
和下面的一样,不同的是匹配到最后(全局匹配)
**preg_match** -- 进行正则表达式匹配,只匹配一次,返回1,否则0,
格式:preg_match("正则表达式","被匹配的字串",存放结果的变量名,PREG_OFFSET_CAPTURE,起始偏移量)
其中:PREG_OFFSET_CAPTURE表示获取匹配索引位置
起始偏移量:从指定位置开始匹配
preg_quote -- 转义正则表达式字符
preg_split -- 用正则表达式分割字符串
**preg_replace** -- 执行正则表达式的搜索和替换
preg_match_all 执行多次
执行一个全局正则表达式匹配
搜索subject中所有匹配pattern给定正则表达式的匹配结果并且将它们以flag指定顺序输出到matches中
在第一个匹配找到后, 子序列继续从最后一次匹配位置搜索
int preg_match_all ( string $pattern , string $subject [, array &$matches [, int $flags = PREG_PATTERN_ORDER [, int $offset = 0 ]]] )
参数 说明:
1.pattern
要搜索的模式,字符串形式。
2.subject
输入字符串。
3.matches
多维数组,作为输出参数输出所有匹配结果, 数组排序通过flags指定。
4.flags
可以结合下面标记使用(注意不能同时使用PREG_PATTERN_ORDER和 PREG_SET_ORDER):
PREG_PATTERN_ORDER(默认)
结果排序为$matches[0]保存完整模式的所有匹配, $matches[1] 保存第一个子组的所有匹配,以此类推。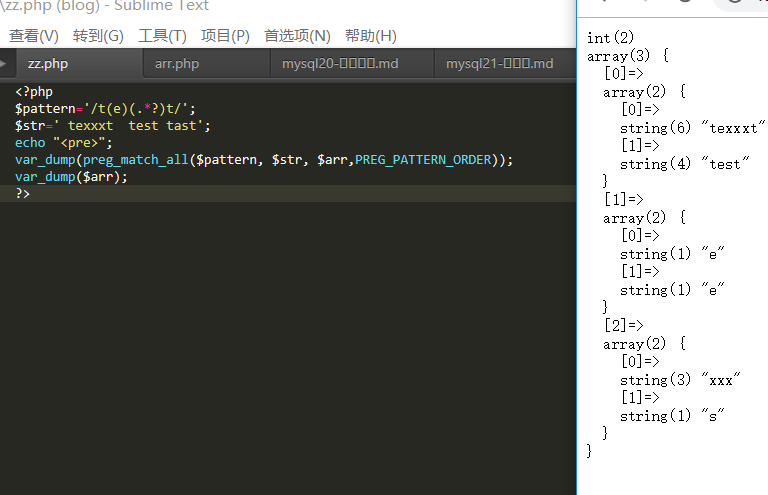
PREG_SET_ORDER
结果排序为$matches[0]包含第一次匹配得到的所有匹配(包含子组), $matches[1]是包含第二次匹配到的所有匹配(包含子组)的数组,以此类推。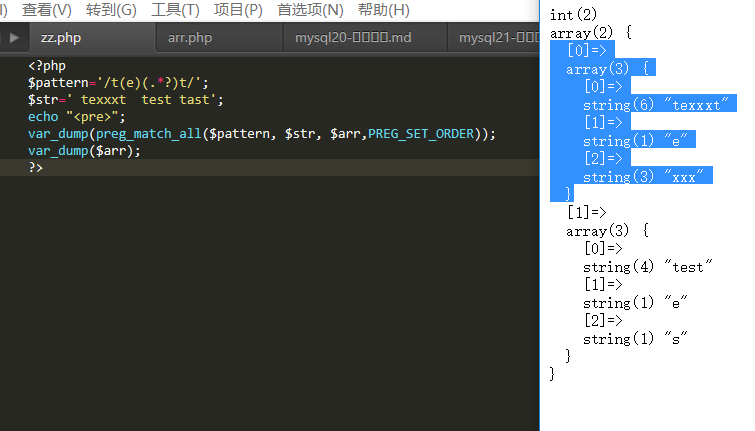
PREG_OFFSET_CAPTURE
如果这个标记被传递,每个发现的匹配返回时会增加它相对目标字符串的偏移量。 注意这会改变matches中的每一个匹配结果字符串元素,使其 成为一个第0个元素为匹配结果字符串,第1个元素为 匹配结果字符串在subject中的偏移量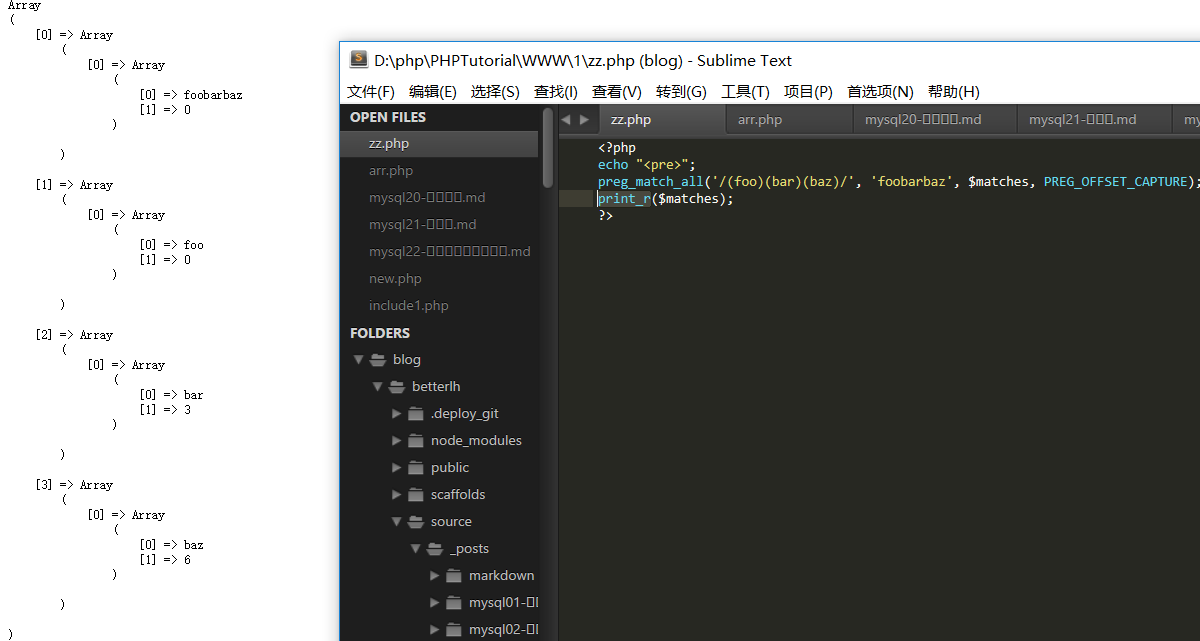
5.offset
通常, 查找时从目标字符串的开始位置开始。可选参数offset用于 从目标字符串中指定位置开始搜索(单位是字节)。
preg_match 执行一次
mixed preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] )
第一个参数:正则表达式:pattern
pattern:要搜索的模式。可以使一个字符串或字符串数组。
第二个参数:要替换的字符串:replacement
第三个参数:目标字符串:subject
要进行搜索和替换的字符串或字符串数组。
如果subject是一个数组,搜索和替换回在subject 的每一个元素上进行, 并且返回值也会是一个数组。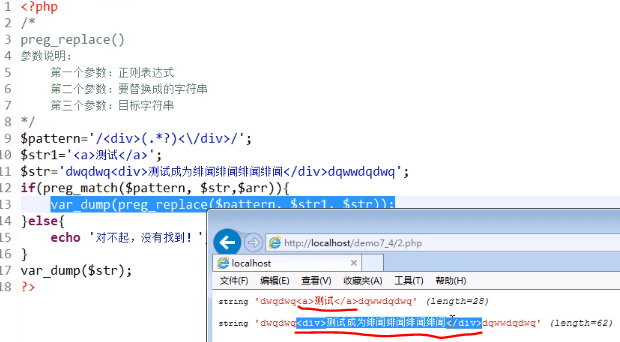
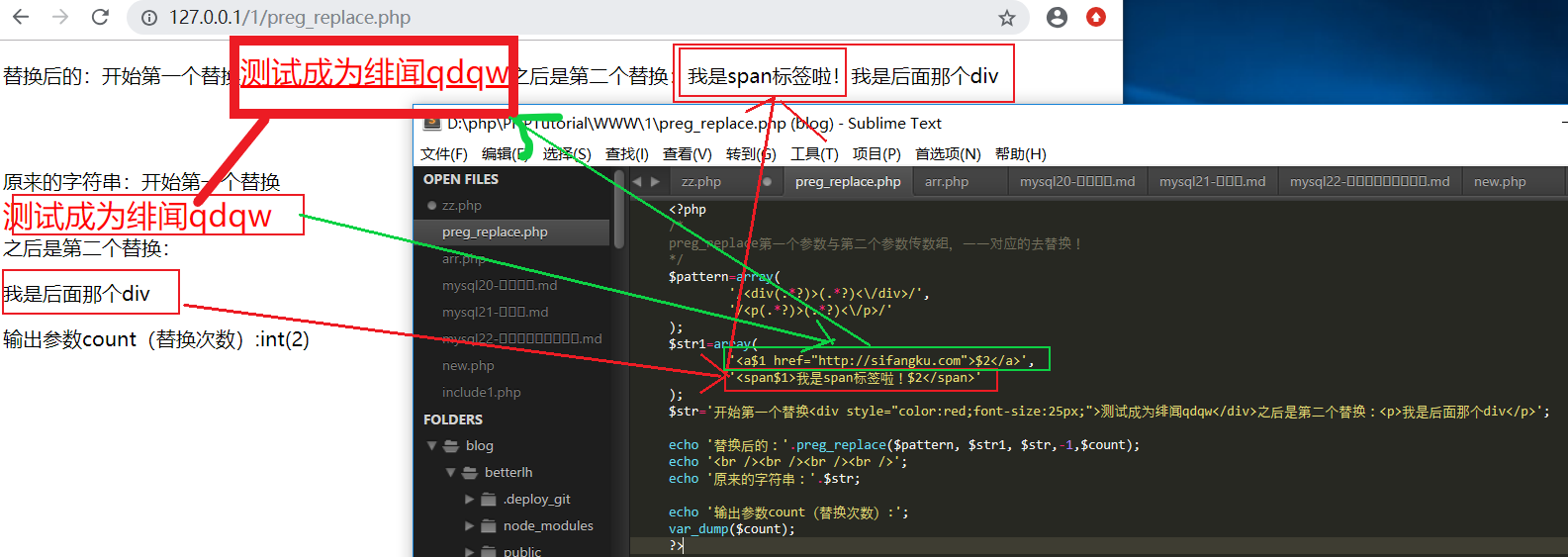
如何使中间部分不变,只将div标签替换成a标签?
联系正则表达式中的()和\\ 由于\\指的使()中的内容,所以我们可以使用\\保留原来的字符串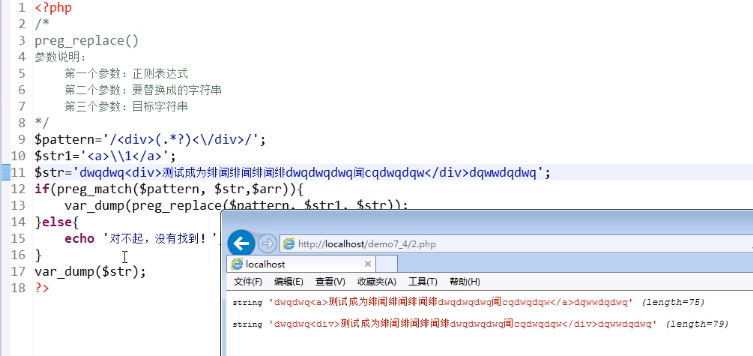
也可以同时替换多个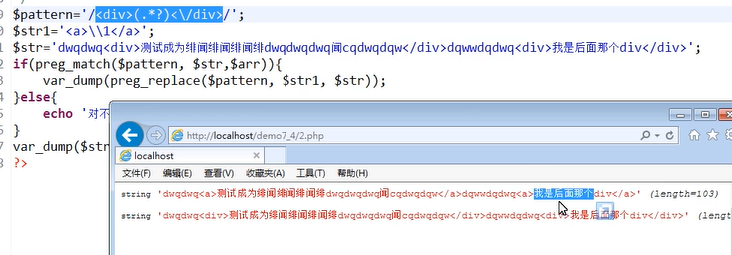
replacement中可以包含反向引用\\n 或$n,语法上首选后者。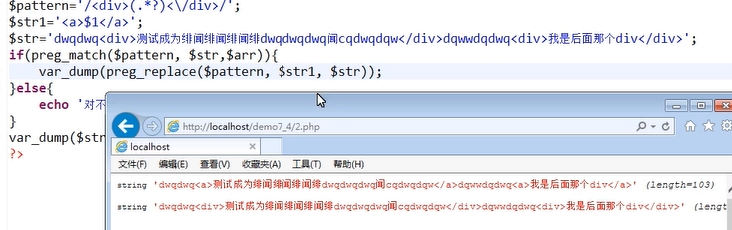
我们还能在标签内部也使用()和对应的反斜杠或$ 来保留标签样式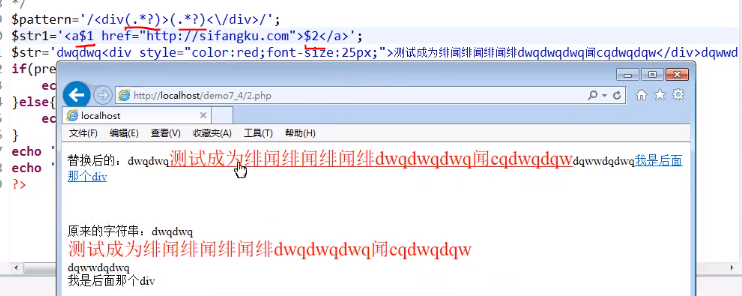
第四个参数limit(可选)
每个模式在每个subject上进行替换的最大次数。默认是 -1(无限)。
第五个参数count(可选)
如果指定,将会被填充为完成的替换次数。
和str_replace一样,第一个参数和第二个参数都可以是数组
如果pattern(第一个参数)和replacement(第二个参数) 都是数组,每个pattern使用replacement中对应的 元素进行替换。如果replacement中的元素比pattern中的少, 多出来的pattern使用空字符串进行替换。